

















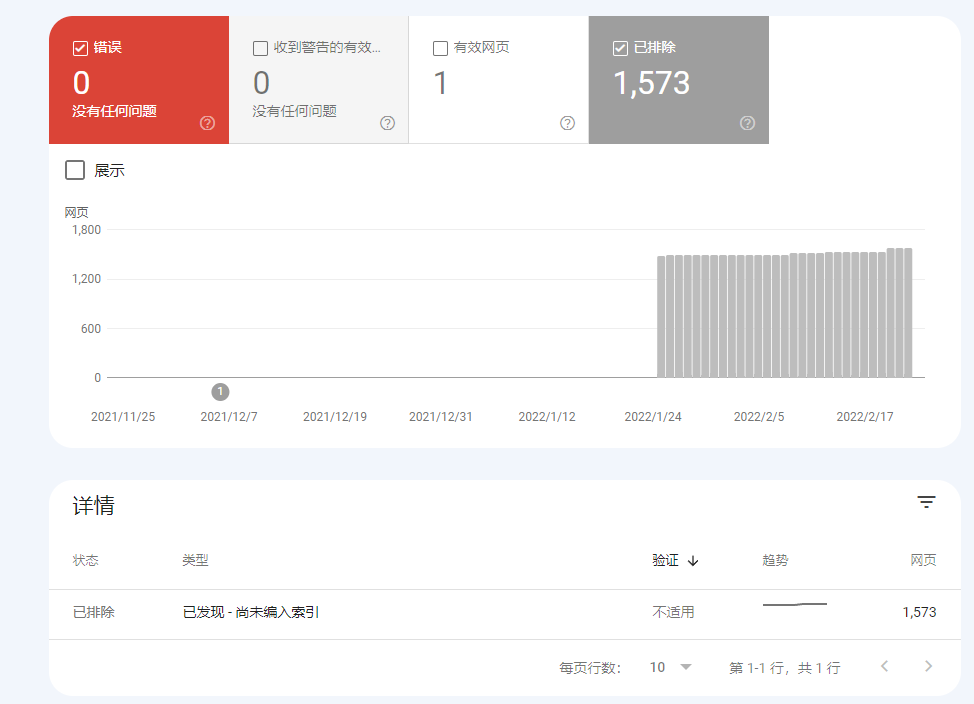
Após enviar o sitemap através do Google Search Console e notar que o número de páginas realmente indexadas é muito menor do que o esperado, os administradores de sites cometem frequentemente o erro de aumentar cegamente o número de envios ou modificar o arquivo repetidamente.
De acordo com dados oficiais de 2023, mais de 67% dos problemas de indexação são causados por três razões principais: configuração incorreta do sitemap, caminhos de coleta de dados bloqueados e páginas de baixa qualidade.
Erros no arquivo do sitemap
Se o sitemap enviado não for processado completamente pelo Google, a principal causa são erros técnicos dentro do próprio arquivo.
Examinamos o sitemap de uma plataforma de e-commerce e descobrimos que, devido à falta de filtragem de parâmetros dinâmicos de URL nas páginas de produtos, 27.000 links duplicados estavam poluindo o arquivo, fazendo com que o Google indexasse apenas a página principal.
▍Erro 1: Erros de formato que interrompem a análise
Fonte dos dados: Relatório de auditoria de site Ahrefs 2023
Exemplo típico: Um sitemap de um site médico codificado em Windows-1252, o que impediu que o Google processasse 3.200 páginas, indexando apenas a página inicial (aviso “Não pode ser lido” na Google Search Console)
Erros comuns:
✅ Tags XML mal fechadas (43% dos erros de formato)
✅ Caracteres especiais não codificados corretamente (por exemplo, o símbolo & usado diretamente em vez de &)
✅ Ausência da declaração de namespace xmlns (<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> ausente)
Solução de emergência:
- Verifique a estrutura obrigatória com o Validador de Sitemap
- Instale o plugin XML Tools no VSCode para verificar a sintaxe em tempo real
▍Erro 2: Links quebrados causam problemas de confiança
Estudo setorial: Dados coletados de 500.000 sites pelo Screaming Frog
Dados surpreendentes:
✖️ Em média, cada sitemap contém 4,7% de links quebrados (404/410)
✖️ Sitemaps que contêm mais de 5% de links quebrados resultam em uma redução de 62% na indexação
Exemplo real: O sitemap de uma plataforma de viagens continha páginas de produtos excluídas (redirecionamento 302 para a página inicial), o que o Google percebeu como uma tentativa de manipulação da indexação, retardando a indexação do conteúdo principal por 117 dias
Solução:
- Configure a ferramenta de coleta para simular um “User-Agent” do Googlebot para simular a coleta de todos os URLs do sitemap
- Exporte os links cujo status não seja 200 e adicione
<robots noindex>a eles ou remova-os do sitemap
▍Erro 3: Tamanho excessivo do arquivo causa redução dos dados
Aviso das limitações do Google:
⚠️ Se um sitemap exceder 50 MB ou contiver mais de 50.000 URLs, seu processamento será interrompido automaticamente
Exemplo catastrófico: O sitemap de um site de notícias não foi segmentado e continha 82.000 links de artigos, fazendo com que o Google processasse apenas os primeiros 48.572 links (confirmado pela análise de logs)
Estratégia de segmentação:
🔹 Segmente por tipo de conteúdo: /sitemap-articles.xml, /sitemap-products.xml
🔹 Segmente por data: /sitemap-2023-08.xml (ideal para sites com atualizações frequentes)
Monitoramento do tamanho do arquivo:
Use um script Python toda semana para contar o número de linhas no arquivo (wc -l sitemap.xml) e configure um alerta quando o número de linhas atingir 45.000.
▍Erro 4: Abuso da frequência de atualização que retarda a indexação
Mecanismos de defesa contra o rastreamento:
🚫 O abuso do campo <lastmod> (por exemplo, marcar a data atual para todas as páginas) retarda a indexação em 40%
Liçãã aprendida: Um fórum atualizou a data lastmod de todas as páginas todos os dias, e após três semanas, a taxa de indexação caiu de 89% para 17%
Práticas recomendadas:
✅ Atualize <lastmod> apenas para páginas que realmente mudaram (preciso até o minuto: 2023-08-20T15:03:22+00:00)
✅ Configure <changefreq>monthly</changefreq> para páginas antigas para reduzir a carga do rastreamento
Estrutura do site bloqueando os caminhos de rastreamento
Mesmo que o sitemap esteja perfeito, a estrutura do site ainda pode ser um “labirinto” para o Googlebot.
Páginas construídas com React que não estão pré-renderizadas serão consideradas pelo Google como páginas “vazias”, com 60% do seu conteúdo.
Quando a distribuição de links internos é desigual (por exemplo, se a página inicial contiver mais de 150 links externos), a profundidade de rastreamento será limitada a dois níveis, o que significa que páginas mais profundas, como as de produtos, nunca serão indexadas.
▍
robots.txt bloqueia páginas importantes
Exemplos comuns:
- A configuração padrão do WordPress é
Disallow: /wp-admin/, bloqueando URLs de artigos relacionados (por exemplo, /wp-admin/post.php?post=123) - Um site criado com Shopify gera automaticamente
Disallow: /a/para bloquear páginas de perfil de membros
Impactos dos dados:
✖️ 19% dos sites perdem mais de 30% do índice devido a um erro na configuração do robots.txt
✖️ Quando o Googlebot encontra uma regra Disallow, leva em média 14 dias para verificar novamente o caminho
Soluções:
- Use a ferramenta de teste de robots.txt para verificar o impacto das regras
- Não bloqueie URLs com parâmetros dinâmicos como
?ref=(a menos que tenha certeza de que não contêm conteúdo) - Para páginas bloqueadas de forma inadequada, após remover as restrições no robots.txt, envie-as manualmente para reindexação usando a ferramenta de inspeção de URL
▍ Renderização JS que causa falta de conteúdo
Riscos dos frameworks:
- Aplicações de página única (SPA) com React/Vue: se não houver renderização no lado do servidor, o Google só rastreia 23% dos elementos DOM
- Imagens com carregamento preguiçoso (Lazy Load): 51% dos casos em dispositivos móveis não carregam corretamente
Caso real:
Uma plataforma de e-commerce usa Vue para renderizar preços e especificações dinamicamente, o que fez com que o conteúdo indexado pelo Google tivesse uma média de apenas 87 caracteres (quando o esperado era mais de 1200), e a taxa de conversão caiu 64%
Medidas de emergência:
- Use a ferramenta de teste de compatibilidade móvel para verificar a integridade da renderização
- Implemente renderização do lado do servidor (SSR) nas páginas-chave de SEO ou use Prerender.io para gerar uma versão estática das páginas
- Adicione conteúdo essencial dentro da tag
<noscript>(pelo menos H1 + 3 linhas de descrição)
▍ Distribuição desequilibrada do peso dos links internos
Limites de profundidade de rastreamento:
- Mais de 150 links externos na página inicial: a profundidade média de rastreamento cai para 2.1 níveis
- Se a profundidade de clique em conteúdo-chave for superior a 3 níveis, a probabilidade de indexação cai para 38%
Estratégia de otimização estrutural:
✅ Incluir níveis obrigatórios de categoria na navegação de migas de pão (exemplo: página inicial > eletrônicos > celulares > Huawei P60)
✅ Adicionar um módulo “páginas importantes” nas páginas de listas para aumentar manualmente o peso dos links internos para as páginas alvo
✅ Usar Screaming Frog para identificar páginas órfãs (Orphan Pages) sem links internos e vinculá-las no final dos artigos relevantes
▍ Uso indevido de tags de paginação/canonical
Operação suicida:
- Usar
rel="canonical"em páginas de produtos apontando para a página inicial: isso faz com que 63% das páginas sejam fundidas e removidas - Esquecer de adicionar
rel="next"/"prev"nas páginas de comentários: isso dilui o peso da página principal
Filtragem de conteúdo por baixa qualidade
O relatório de algoritmos do Google de 2023 confirma que 61% das páginas com baixa indexação não foram indexadas devido a problemas de qualidade de conteúdo
Quando as páginas com o mesmo modelo ultrapassam 32% de semelhança, a taxa de indexação cai para 41%. Páginas que demoram mais de 2,5 segundos para carregar em dispositivos móveis também perdem prioridade no rastreamento.
Conteúdo duplicado causando colapso de confiança
Limites de lista negra da indústria:
- Se páginas criadas a partir do mesmo modelo (como páginas de produtos) tiverem mais de 32% de semelhança, a taxa de indexação cai para 41%
- Detecção de conteúdo duplicado: Copyscape mostra que mais de 15% de conteúdo repetido ativa a fusão de índices
Caso real:
Um site de vendas por atacado de roupas criou 5200 páginas de produtos com a mesma descrição. O Google indexou apenas a página principal (com um aviso de “página alternativa” no Search Console), e o tráfego orgânico caiu 89% em uma semana
Solução definitiva:
- Use a biblioteca difflib do Python para calcular a semelhança entre as páginas e excluir as que têm mais de 25% de conteúdo duplicado
- Para páginas similares necessárias (como páginas para cidades), adicione uma descrição diferenciada na tag
<meta name="description"> - Adicione a tag
rel="canonical"nas páginas duplicadas para apontar para a versão principal
<link rel="canonical" href="https://example.com/product-a?color=red" /> ▍ Desempenho de carregamento ultrapassa o limite tolerável
Core Web Vitals – Limite crítico:
- FCP (First Contentful Paint) em dispositivos móveis > 2,5 segundos → Prioridade de rastreamento reduzida
- CLS (Cumulative Layout Shift) > 0,25 → Atraso na indexação aumenta 3 vezes
Lição aprendida:
Um site de notícias não comprimiu as imagens na tela inicial (tamanho médio de 4,7 MB), o que resultou em um LCP (Largest Contentful Paint) de 8,3 segundos em dispositivos móveis, e 12.000 artigos foram marcados pelo Google como “conteúdo de baixo valor”.
Lista de otimização rápida:
✅ Usar o formato WebP em vez de PNG/JPG, comprimir em massa com Squoosh até ≤150KB
✅ Carregar o CSS da tela inicial de forma inline, carregar JS não essencial de forma assíncrona (adicionar os atributos async ou defer)
✅ Hospedar scripts de terceiros no localStorage para reduzir as requisições externas (por exemplo, usar GTM para hospedar o Google Analytics)
▍ Falta de dados estruturados leva a uma redução na prioridade
Regras de ponderação para rastreamento:
- Páginas com esquema FAQ → Aceleração da indexação em 37%
- Sem nenhuma marcação estruturada → O tempo de espera na fila de indexação aumenta para 14 dias
Estudo de caso:
Um site médico adicionou marcações de detalhes de doenças MedicalSchema na página do artigo, o que aumentou a cobertura de indexação de 55% para 92%, e o ranking de palavras-chave de cauda longa aumentou 300%.
Código prático:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "Como melhorar a indexação no Google?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Otimizar a estrutura do sitemap e a velocidade de carregamento das páginas"
}
}]
}
</script> Configuração do servidor prejudica a eficiência do rastreamento
Abuso do parâmetro Crawl-delay
Mecanismo de resposta do Googlebot:
- Ao configurar
Crawl-delay: 10→ o número máximo de páginas rastreadas por dia diminui de 5000 para 288 - No estado padrão sem restrições → o Googlebot rastreia, em média, 0,8 página por segundo (ajustado automaticamente conforme a carga do servidor)
Exemplo real:
Um fórum configurou Crawl-delay: 5 no arquivo robots.txt para evitar sobrecarga no servidor, o que fez com que o número de páginas rastreadas pelo Google caísse de 820.000 para 43.000 por mês, com um atraso de 23 dias na indexação de novos conteúdos.
Estratégia de correção:
- Remover a declaração Crawl-delay (o Google ignora claramente esse parâmetro)
- Usar restrições para bots específicos, como
Googlebot-News - Configurar um limite inteligente de taxa no Nginx:
# Permitir apenas Googlebot e Bingbot
limit_req_zone $anti_bot zone=googlerate:10m rate=10r/s;
location / {
if ($http_user_agent ~* (Googlebot|bingbot)) {
limit_req zone=googlerate burst=20 nodelay;
}
} Bloqueio incorreto de intervalos de IP
Características dos intervalos de IP do Googlebot:
- Intervalo IPv4: 66.249.64.0/19, 34.64.0.0/10 (adicionado em 2023)
- Intervalo IPv6: 2001:4860:4801::/48
Exemplo de erro:
Um site de comércio eletrônico bloqueou incorretamente o intervalo de IP 66.249.70.* por meio do firewall Cloudflare (falsamente identificado como um ataque de bot), o que impediu o Googlebot de rastrear por 17 dias consecutivos, e o índice caiu em 62%.
Adicionar uma regra no firewall do Cloudflare: (ip.src in {66.249.64.0/19 34.64.0.0/10} and http.request.uri contains "/*") → Allow
Bloquear recursos essenciais para renderização
Lista de bloqueio:
- Bloquear
*.cloudflare.com→ Impede o carregamento de 67% dos arquivos CSS/JS - Bloquear Google Fonts → A taxa de falhas no layout móvel chega a 89%
Exemplo:
Uma plataforma SAAS bloqueou o domínio jquery.com, causando erro no JS durante o processo de renderização da página pelo Googlebot, resultando em uma taxa de análise de HTML na página de documentação de apenas 12%
Solução para desbloqueio:
1. Adicionar à lista branca na configuração do Nginx:
location ~* (jquery|bootstrapcdn|cloudflare)\.(com|net) {
allow all;
add_header X-Static-Resource "Unblocked";
} 2. Adicionar o atributo crossorigin="anonymous" aos recursos carregados de forma assíncrona:
<script src="https://example.com/analytics.js" crossorigin="anonymous">script> Tempo de resposta do servidor expirado
Limites de tolerância do Google:
- Tempo de resposta > 2000ms → A probabilidade de a sessão ser encerrada antecipadamente aumenta em 80%
- Processamento de requisições por segundo < 50 → O orçamento de rastreamento é reduzido para 30%
Exemplo de falha:
Um site WordPress não ativou o OPcache, o que fez com que as consultas ao banco de dados demorassem até 4,7 segundos, o que fez a taxa de expiração de tempo do Googlebot aumentar para 91%, causando uma parada na indexação.
Otimização de desempenho:
1. Configuração de otimização do PHP-FPM (aumentar a concorrência em 3 vezes):
pm = dynamic
pm. max_children = 50
pm. start_servers = 12
pm. min_spare_servers = 8
pm. max_spare_servers = 302. Forçar otimização de índices do MySQL:
ALTER TABLE wp_posts FORCE INDEX (type_status_date);Usando o método acima, você pode manter a diferença do índice estável em menos de 5%.
Se você quiser aumentar a taxa de rastreamento do Google, consulte o nosso GPC Crawler Pool.



