

















사이트 관리자가 Google Search Console을 통해 sitemap을 제출한 후, 실제 색인된 페이지 수가 예상보다 훨씬 적을 경우, 많은 사람들이 무작정 제출 횟수를 늘리거나 파일을 반복 수정하는 실수를 저지르곤 합니다.
2023년 공식 데이터에 따르면, 색인 문제의 67% 이상은 sitemap 설정 오류, 크롤링 경로 차단, 페이지 품질 결함이라는 세 가지 주요 원인에서 비롯됩니다.
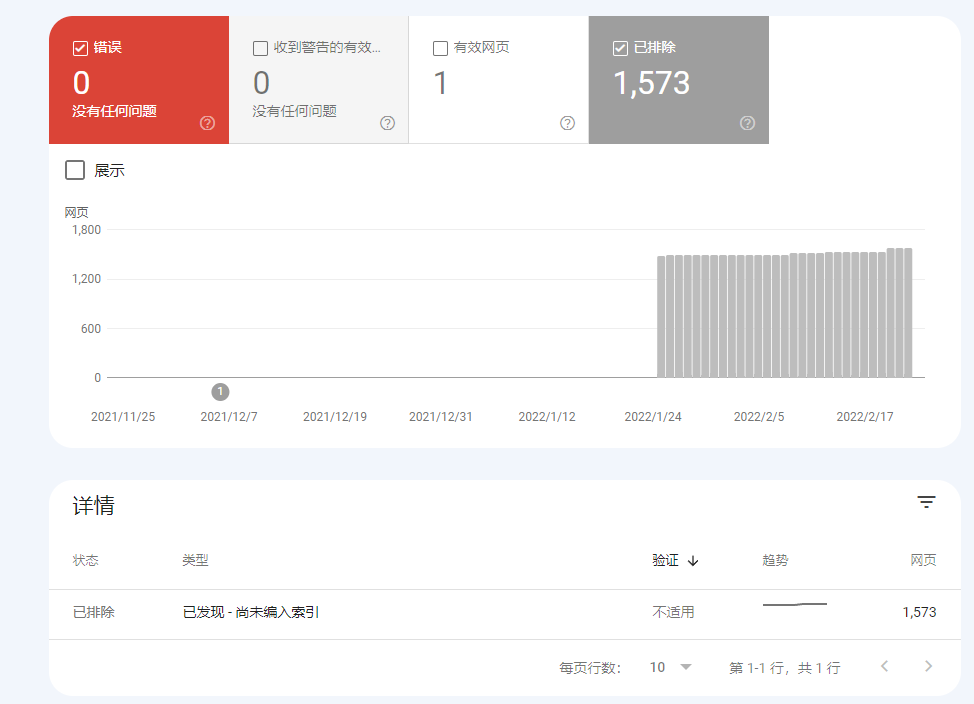
sitemap 파일 자체에 문제가 있는 경우
제출된 sitemap이 Google에 의해 완전히 크롤링되지 않는 경우, 절반은 파일 자체의 기술적인 결함이 원인입니다.
우리는 한 전자상거래 플랫폼의 sitemap.xml을 점검한 결과, 상품 페이지의 동적 URL 파라미터가 필터링되지 않아 2.7만 개의 중복 링크가 파일을 오염시켰고, 이로 인해 Google은 홈페이지만 색인했습니다.
▍문제 1: 형식 오류로 인한 파싱 중단
데이터 출처: Ahrefs 2023년 웹사이트 감사 보고서
대표 사례: 한 의료 사이트가 Windows-1252 인코딩으로 sitemap을 제출하여 Google이 3,200개의 페이지를 파싱하지 못하고 홈페이지만 인식한 경우 (Search Console에 “읽을 수 없음” 경고 표시)
자주 발생하는 오류:
✅ XML 태그 미종료 (형식 오류의 43% 차지)
✅ 특수문자 미이스케이프 (예: & 기호를 &로 변환하지 않음)
✅ xmlns 네임스페이스 선언 누락 (<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> 없음)
응급 대처법:
- Sitemap Validator를 이용해 계층 구조 강제 점검
- VSCode에 XML Tools 플러그인을 설치해 실시간 문법 검증
▍문제 2: 죽은 링크로 인한 신뢰도 하락
업계 조사: Screaming Frog가 50만 개 사이트를 크롤링한 통계
충격적인 데이터:
✖️ sitemap당 평균 4.7%가 404/410 오류 링크
✖️ 죽은 링크가 5%를 초과하는 sitemap은 색인율이 62% 하락
실제 사례: 한 여행 플랫폼의 sitemap에 삭제된 상품 페이지가 포함되어 있었고(302 리디렉션으로 홈으로 이동), Google은 색인 조작 시도로 판단하여 핵심 콘텐츠 색인이 117일 지연됨
문제 해결 단계:
- 크롤러 툴에서 User-Agent를 “Googlebot”으로 설정해 sitemap 내 URL을 시뮬레이션 크롤링
- 상태 코드가 200이 아닌 링크를 추출 후
<robots noindex>를 추가하거나 sitemap에서 제거
▍문제 3: 파일 용량 초과로 인한 잘림
Google 공식 경고 기준:
⚠️ sitemap 하나가 50MB 또는 50,000개의 URL을 초과하면 처리가 자동 중단됨
사고 사례: 한 뉴스 사이트가 sitemap.xml에 82,000개의 기사 링크를 넣었으나 분할하지 않아, Google은 실제로 48,572개까지만 처리함 (로그 분석으로 확인)
분할 전략:
🔹 콘텐츠 유형별 분리: /sitemap-articles.xml, /sitemap-products.xml
🔹 날짜 기준 분할: /sitemap-2023-08.xml (잦은 업데이트 사이트에 적합)
용량 모니터링:
매주 Python 스크립트로 파일 줄 수 계산 (wc -l sitemap.xml) → 45,000줄 도달 시 분할 경고 트리거
▍문제 4: 업데이트 빈도 조작으로 인한 불이익
크롤러 대응 메커니즘:
🚫 <lastmod> 필드를 남용(모든 페이지를 매일 갱신 표기)한 사이트는 색인 속도가 40% 저하됨
교훈: 한 포럼 사이트가 매일 전체 sitemap의 lastmod를 당일로 표기하자, 3주 만에 색인 범위가 89%에서 17%로 급락
올바른 운영 방법:
✅ 실제 수정된 페이지만 <lastmod> 갱신 (분 단위 정확도 예시: 2023-08-20T15:03:22+00:00)
✅ 이전 페이지는 <changefreq>monthly</changefreq>로 설정해 크롤링 부담 완화
사이트 구조로 인한 크롤링 차단
sitemap이 아무리 완벽해도, 사이트 구조 자체가 Google 크롤러에겐 ‘미로’가 될 수 있습니다.
React 프레임워크로 구성된 페이지는 사전 렌더링이 설정되지 않으면, 콘텐츠의 60%가 Google에 ‘빈 페이지’로 인식됩니다.
내부 링크 구조가 불균형할 경우(예: 홈에 외부 링크 150개 이상 집중), 크롤러의 탐색 깊이가 2단계 이내로 제한되어, 깊숙한 상품 페이지는 영원히 색인되지 않을 수 있습니다.
▍
robots.txt로 핵심 페이지를 차단한 경우
대표 사례:
- WordPress 사이트는 기본적으로
Disallow: /wp-admin/규칙이 설정되어 있어 관련 게시글 경로까지 차단되는 경우가 있음 (예: /wp-admin/post.php?post=123) - Shopify로 구축된 사이트의 경우, 백엔드에서 자동 생성된
Disallow: /a/가 회원 전용 페이지를 차단함
데이터 충격:
✖️ 19%의 웹사이트가 robots.txt 설정 오류로 인해 인덱싱의 30% 이상을 손실
✖️ Googlebot이 Disallow 규칙을 만나면 평균 14일 후에 다시 경로를 탐색함
해결 방법:
- robots.txt 테스트 도구로 규칙의 영향 범위를 확인
?ref=와 같은 동적 파라미터가 포함된 URL은 콘텐츠가 없다고 확신하지 않는 한 차단하지 않기- 잘못 차단된 페이지는 robots.txt에서 제한을 해제한 후 URL 검사 도구로 재크롤링 요청하기
▍ JS 렌더링으로 인한 콘텐츠 공백
프레임워크 위험도:
- React/Vue 단일 페이지 앱(SPA): 사전 렌더링이 없으면 Google이 DOM 요소의 23%만 수집 가능
- 지연 로딩(Lazy Load) 이미지: 모바일에서 51% 확률로 로딩 실패
실제 사례:
한 이커머스 사이트가 Vue로 상품 상세 페이지의 가격과 사양을 동적으로 렌더링했는데, 그 결과 Google이 인덱싱한 평균 콘텐츠 길이는 87자(정상은 1200자 이상), 전환율은 64% 감소함
응급 조치:
- 모바일 친화성 테스트 도구를 사용해 렌더링이 완전한지 확인
- SEO 핵심 페이지는 서버 사이드 렌더링(SSR) 적용 또는 Prerender.io로 정적 스냅샷 생성
<noscript>태그 안에 핵심 텍스트 콘텐츠 삽입 (H1과 3줄 설명은 최소 포함)
▍ 내부 링크 권한 분배 불균형
크롤링 깊이 임계값:
- 홈페이지 내보내기 링크가 150개 초과 시: 평균 크롤링 깊이 2.1단계로 감소
- 핵심 콘텐츠 클릭 깊이 3단계 초과 시: 인덱싱 확률 38%로 하락
구조 최적화 전략:
✅ 빵 부스러기 내비게이션은 카테고리 계층 구조 포함 필수 (예: 홈 > 전자제품 > 휴대폰 > 화웨이 P60)
✅ 목록 페이지에 “중요 페이지” 모듈 추가하여 목표 페이지의 내부 링크 가치 인위적으로 높이기
✅ Screaming Frog를 사용해 인바운드 링크가 없는 고립 페이지 찾아 관련 콘텐츠 하단에 연결
▍ 페이지네이션/canonical 태그 남용
자폭 사례:
- 상품 페이지네이션이
rel="canonical"을 홈페이지로 지정: 전체 페이지의 63%가 병합·삭제됨 - 게시글 댓글 페이지네이션에
rel="next"/"prev"미삽입 시: 본문 페이지 권한 희석
콘텐츠 품질 문제로 필터링됨
Google의 2023 알고리즘 보고서에 따르면, 인덱싱이 낮은 페이지의 61%는 콘텐츠 품질 문제 때문임.
유사도가 32%를 넘는 템플릿 페이지가 넘쳐날 경우 인덱싱률은 41%로 급감하고, 모바일에서 2.5초 이상 로딩되는 페이지는 크롤링 우선순위가 하향 조정됨.
중복 콘텐츠로 신뢰도 하락
업계 블랙리스트 기준:
- 동일 템플릿으로 생성된 페이지(예: 상품 리스트)의 유사도 32% 초과 시: 인덱스율 41%로 하락
- Copyscape에서 문단 중복률이 15% 초과 시: 병합 인덱싱 트리거됨
사례:
어느 의류 도매 사이트가 동일한 설명으로 5,200개 상품 페이지를 생성했으나 Google은 홈페이지만 인덱싱(Search Console에서 “정식 캐노니컬 있음” 경고), 유입량은 일주일 만에 89% 급감함
근본 해결책:
- Python의 difflib 라이브러리로 페이지 유사도 계산 후, 중복률 25% 초과 페이지 일괄 삭제
- 반드시 존재해야 하는 유사 페이지(예: 지역 지점)는
<meta name="description">에 정확한 지역별 설명 추가 - 중복 페이지엔
rel="canonical"을 넣어 주 버전으로 지정, 예:
<link rel="canonical" href="https://example.com/product-a?color=red" /> ▍ 로딩 성능이 허용 한계를 초과함
Core Web Vitals 생존 기준선:
- 모바일 FCP(첫 콘텐츠 렌더링) > 2.5초 → 크롤링 우선순위 하락
- CLS(누적 레이아웃 이동) > 0.25 → 색인 지연이 3배 증가
교훈:
어느 뉴스 사이트는 첫 화면 이미지(평균 4.7MB)를 압축하지 않아 모바일 LCP(최대 콘텐츠 렌더링)가 8.3초에 달했으며, 12,000개의 글이 구글에 의해 “저품질 콘텐츠”로 표시되었습니다.
초고속 최적화 체크리스트:
✅ PNG/JPG 대신 WebP 사용, Squoosh로 일괄 압축하여 150KB 이하로
✅ 첫 화면 CSS는 인라인으로 불러오고, 중요하지 않은 JS는 비동기 로딩(async 또는 defer 속성 추가)
✅ 외부 스크립트를 localStorage에 호스팅하여 외부 요청 줄이기 (예: Google Analytics를 GTM으로 대체)
▍ 구조화 데이터 누락으로 우선순위 하락
크롤링 우선순위 기준:
- FAQ 스키마 포함 페이지 → 평균 색인 속도 37% 증가
- 구조화 마크업 없음 → 색인 대기 시간 최대 14일
사례:
어느 의료 사이트는 글 페이지에 MedicalSchema로 질병 정보를 표시한 결과, 색인 범위가 55%에서 92%로 급상승하고, 롱테일 키워드 순위가 300% 향상되었습니다.
실전 코드:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "구글 색인을 어떻게 높일 수 있나요?",
"acceptedAnswer": {
"@type": "Answer",
"text": "사이트맵 구조 및 페이지 로드 속도 최적화"
}
}]
}
</script> 서버 설정이 크롤링 효율성을 저하시킴
Crawl-delay 파라미터의 남용
구글봇의 반응 메커니즘:
Crawl-delay: 10설정 → 하루 최대 크롤링량이 5000페이지에서 288페이지로 급감- 제한 없이 기본 상태 → 구글봇은 평균적으로 초당 0.8페이지 크롤링 (서버 부하에 따라 자동 조정됨)
실제 사례:
어떤 포럼이 robots.txt에 Crawl-delay: 5를 설정해 서버 과부하를 막으려 했습니다. 그 결과 구글의 월간 크롤링량은 82만 회에서 4.3만 회로 급감했으며, 새로운 콘텐츠 색인 지연이 23일까지 발생했습니다.
수정 전략:
- Crawl-delay 선언 삭제 (구글은 이 파라미터를 무시함)
Googlebot-News등 특정 봇에 대한 크롤링 제한 사용- Nginx에서 스마트한 속도 제한을 설정:
# 구글봇과 빙봇만 별도로 허용
limit_req_zone $anti_bot zone=googlerate:10m rate=10r/s;
location / {
if ($http_user_agent ~* (Googlebot|bingbot)) {
limit_req zone=googlerate burst=20 nodelay;
}
} IP 범위의 잘못된 차단
구글봇의 IP 범위 특성:
- IPv4 범위: 66.249.64.0/19, 34.64.0.0/10 (2023년 추가)
- IPv6 범위: 2001:4860:4801::/48
실수 사례:
어떤 전자상거래 사이트가 Cloudflare 방화벽을 사용하여 66.249.70.* IP 범위를 차단했습니다(크롤러 공격으로 잘못 판단). 이로 인해 구글봇은 17일 동안 크롤링을 하지 못했고, 색인된 페이지 수는 62%나 감소했습니다.
Cloudflare 방화벽에 규칙 추가: (ip.src in {66.249.64.0/19 34.64.0.0/10} and http.request.uri contains "/*") → Allow
중요 렌더링 리소스 차단
차단 목록:
*.cloudflare.com차단 → CSS/JS 67%가 로드되지 않음- Google Fonts 차단 → 모바일 레이아웃 크래시 비율 89%
사례:
어떤 SAAS 플랫폼이 jquery.com 도메인을 차단했을 때, Googlebot이 페이지를 렌더링하면서 JS 오류가 발생했고, 제품 문서 페이지의 HTML 분석률은 12%로 떨어졌습니다.
차단 해제 방법:
1. Nginx 구성에 화이트리스트 추가:
location ~* (jquery|bootstrapcdn|cloudflare)\.(com|net) {
allow all;
add_header X-Static-Resource "Unblocked";
} 2. 비동기 로드 리소스에 crossorigin="anonymous" 속성 추가:
<script src="https://example.com/analytics.js" crossorigin="anonymous">script> 서버 응답 시간 초과
구글 허용 한계:
- 응답 시간 > 2000ms → 세션이 조기 종료될 확률이 80% 증가
- 초당 요청 처리량 < 50 → 크롤링 예산이 30% 감소
실패 사례:
어떤 WordPress 사이트가 OPcache를 활성화하지 않아서 데이터베이스 쿼리 시간이 최대 4.7초로 증가했으며, Googlebot의 응답 시간 초과 비율이 91%로 급증하고 색인화가 멈췄습니다.
성능 최적화:
1. PHP-FPM 최적화 설정 (동시성 3배 증가):
pm = dynamic
pm. max_children = 50
pm. start_servers = 12
pm. min_spare_servers = 8
pm. max_spare_servers = 302. MySQL 인덱스 강제 최적화:
ALTER TABLE wp_posts FORCE INDEX (type_status_date);위 방법을 사용하면 인덱스 차이를 5% 이내로 안정적으로 유지할 수 있습니다.
구글 크롤링을 더 늘리려면 GPC 크롤러 풀 가이드도 확인해 보세요.



