

















Sau khi quản trị viên web gửi sơ đồ trang web qua Google Search Console và nhận thấy số lượng trang được lập chỉ mục thực tế ít hơn dự đoán, họ thường mắc phải sự hiểu lầm là tăng số lần gửi một cách mù quáng hoặc sửa đổi tệp một cách lặp đi lặp lại.
Theo dữ liệu chính thức năm 2023, hơn 67% các vấn đề liên quan đến việc lập chỉ mục xuất phát từ 3 nguyên nhân chính: sai cấu hình sơ đồ trang web, chặn các đường dẫn thu thập dữ liệu, và thiếu sót về chất lượng trang.
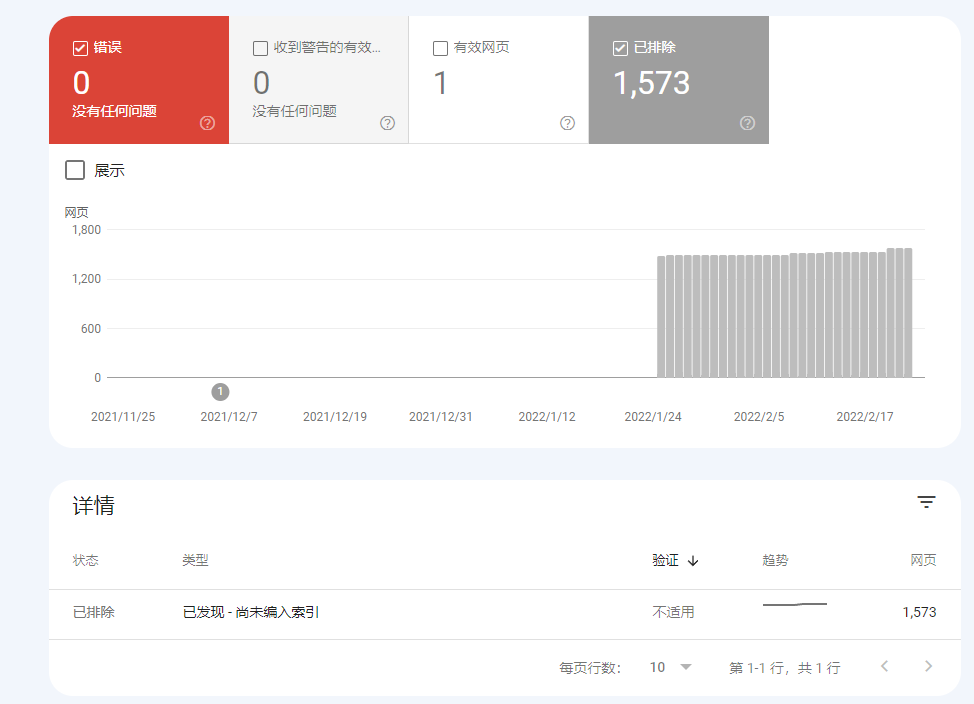
Điểm yếu trong tệp sơ đồ trang web
Khi sơ đồ trang web đã gửi không thể được Google thu thập dữ liệu đầy đủ, nguyên nhân chủ yếu là do các lỗi kỹ thuật trong chính tệp đó.
Chúng tôi đã kiểm tra sơ đồ trang web của một nền tảng thương mại điện tử và phát hiện ra rằng, do thiếu lọc tham số URL động cho các trang sản phẩm, đã có 27.000 liên kết trùng lặp làm ô nhiễm tệp, khiến Google chỉ lập chỉ mục trang chủ mà thôi.
▍Điểm yếu 1: Lỗi định dạng khiến việc phân tích bị gián đoạn
Nguồn dữ liệu: Báo cáo kiểm tra trang web của Ahrefs năm 2023
Trường hợp điển hình: Một trang web y tế gửi sơ đồ trang web được mã hóa bằng Windows-1252, khiến Google không thể phân tích được 3.200 trang và chỉ nhận diện được trang chủ (cảnh báo “không thể đọc” trong Search Console)
Các lỗi thường gặp:
✅ Các thẻ XML không được đóng đúng cách (43% lỗi định dạng)
✅ Ký tự đặc biệt không được mã hóa (ví dụ: ký tự & sử dụng trực tiếp thay vì mã hóa thành &)
✅ Thiếu khai báo không gian tên xmlns (<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> thiếu)
Giải pháp khẩn cấp:
- Kiểm tra cấu trúc bắt buộc bằng Sitemap Validator
- Cài đặt plugin XML Tools trên VSCode để kiểm tra cú pháp theo thời gian thực
▍Điểm yếu 2: Liên kết chết gây ra vấn đề về độ tin cậy
Nghiên cứu ngành: Dữ liệu thu thập từ 500.000 trang web của Screaming Frog
Dữ liệu gây ngạc nhiên:
✖️ Trung bình sơ đồ trang web chứa 4.7% liên kết lỗi 404/410
✖️ Các sơ đồ trang web chứa hơn 5% liên kết chết sẽ làm giảm tỷ lệ lập chỉ mục xuống 62%
Trường hợp thực tế: Sơ đồ trang web của một trang web du lịch chứa các trang sản phẩm bị xóa (được chuyển hướng 302 về trang chủ), khiến Google coi đây là thao tác thao túng chỉ mục, dẫn đến việc lập chỉ mục trang chủ bị trễ 117 ngày
Các bước xử lý vấn đề:
- Cấu hình lại User-Agent của công cụ thu thập dữ liệu thành “Googlebot” để mô phỏng việc thu thập dữ liệu tất cả các liên kết trong sơ đồ trang web
- Xuất các liên kết không phải mã trạng thái 200 và thêm
<robots noindex>hoặc xóa liên kết khỏi sơ đồ trang web
▍Điểm yếu 3: Vượt quá giới hạn kích thước tệp gây ra việc cắt giảm dữ liệu
Cảnh báo giới hạn từ Google:
⚠️ Nếu tệp sơ đồ trang web vượt quá 50MB hoặc chứa hơn 50.000 URL, việc xử lý sẽ tự động bị dừng lại
Trường hợp thảm họa: Sơ đồ trang web của một trang tin tức không được chia nhỏ và chứa 82.000 liên kết bài viết, khiến Google chỉ xử lý được 48.572 liên kết đầu tiên (đã xác nhận qua phân tích nhật ký)
Chiến lược phân chia:
🔹 Chia theo loại nội dung: /sitemap-articles.xml, /sitemap-products.xml
🔹 Chia theo ngày: /sitemap-2023-08.xml (phù hợp với các trang web cập nhật thường xuyên)
Giám sát kích thước tệp:
Sử dụng script Python mỗi tuần để đếm số dòng trong tệp (wc -l sitemap.xml) và tạo cảnh báo khi số dòng đạt 45.000
▍Điểm yếu 4: Lạm dụng tần suất cập nhật khiến việc lập chỉ mục chậm lại
Biện pháp chống lại công cụ thu thập dữ liệu:
🚫 Việc lạm dụng trường <lastmod> (ví dụ: đánh dấu ngày hiện tại trên tất cả các trang) làm giảm tốc độ lập chỉ mục xuống 40%
Bài học rút ra: Một trang web diễn đàn đã cập nhật ngày lastmod trên tất cả các trang mỗi ngày, và trong vòng ba tuần, tỷ lệ lập chỉ mục giảm từ 89% xuống 17%
Hoạt động tuân thủ:
✅ Chỉ cập nhật <lastmod> cho các trang thực sự có thay đổi (chính xác đến từng phút: 2023-08-20T15:03:22+00:00)
✅ Cài đặt <changefreq>monthly</changefreq> cho các trang cũ để giảm tải cho công cụ thu thập dữ liệu
Cấu trúc trang web chặn đường thu thập dữ liệu
Dù sơ đồ trang web có hoàn hảo đến đâu, cấu trúc trang web vẫn có thể là một “mê cung” đối với công cụ thu thập dữ liệu của Google.
Các trang được xây dựng bằng React nếu không được render trước sẽ bị Google coi là “trang trắng” với 60% nội dung của nó.
Khi liên kết nội bộ phân bổ không đồng đều (ví dụ: trang chủ có hơn 150 liên kết ngoài), độ sâu thu thập dữ liệu sẽ bị giới hạn trong 2 lớp, khiến các trang sản phẩm sâu không bao giờ được lập chỉ mục.
▍
robots.txt chặn các trang quan trọng
Trường hợp điển hình:
- Cấu hình mặc định của trang WordPress là
Disallow: /wp-admin/, có thể chặn các đường dẫn bài viết liên quan (ví dụ: /wp-admin/post.php?post=123) - Trang web xây dựng bằng Shopify tự động tạo
Disallow: /a/để chặn các trang hồ sơ thành viên
Dữ liệu từ dữ liệu:
✖️ 19% các trang web có lỗi trong cấu hình robots.txt khiến mất hơn 30% số lượng trang được lập chỉ mục
✖️ Khi Googlebot gặp quy tắc Disallow, sẽ mất trung bình 14 ngày để thử lại
Cách khắc phục:
- Sử dụng Công cụ kiểm tra robots.txt để kiểm tra phạm vi ảnh hưởng của quy tắc
- Không chặn URL có tham số động như
?ref=trừ khi bạn chắc chắn rằng không có nội dung - Đối với các trang bị chặn sai, gỡ bỏ hạn chế trong robots.txt và yêu cầu Googlebot kiểm tra lại qua công cụ Kiểm tra URL
▍ Vấn đề với việc render JS làm mất nội dung
Rủi ro từ Framework:
- React/Vue ứng dụng một trang (SPA): Nếu không render trước, Google chỉ có thể thu thập được 23% phần tử DOM
- Ảnh tải lười (Lazy Load): 51% khả năng không được tải trên di động
Trường hợp thực tế:
Một trang web thương mại điện tử sử dụng Vue để render động giá cả và thông số kỹ thuật sản phẩm. Kết quả là, chiều dài trung bình của nội dung trang được lập chỉ mục bởi Google chỉ có 87 ký tự (thường là hơn 1200 ký tự), tỷ lệ chuyển đổi giảm 64%
Biện pháp khẩn cấp:
- Sử dụng Công cụ kiểm tra tính thân thiện với di động để kiểm tra tính đầy đủ của việc render
- Sử dụng render phía máy chủ (SSR) hoặc tạo snapshot tĩnh cho các trang SEO quan trọng với Prerender.io
- Chèn nội dung quan trọng vào trong thẻ
<noscript>(ít nhất là H1 và 3 dòng mô tả)
▍ Phân bổ quyền lực liên kết nội bộ không đồng đều
Ngưỡng độ sâu thu thập:
- Nếu trang chủ có hơn 150 liên kết ngoài: Độ sâu thu thập giảm xuống còn 2,1 lớp trung bình
- Nếu nội dung chính nằm sâu hơn 3 lớp: Xác suất được lập chỉ mục giảm xuống 38%
Chiến lược tối ưu hóa cấu trúc:
✅ Sử dụng breadcrumb navigation có đầy đủ cấu trúc phân loại (ví dụ: Trang chủ > Thiết bị điện tử > Điện thoại di động > Huawei P60)
✅ Thêm mục “Trang quan trọng” vào các trang danh sách để tăng quyền lực liên kết nội bộ cho các trang mục tiêu
✅ Sử dụng Screaming Frog để tìm các trang cô lập không có liên kết inbound và thêm liên kết vào phần cuối các bài viết có liên quan
▍ Lạm dụng thẻ pagination/canonical
Hành động tự hủy:
- Đặt
rel="canonical"của trang sản phẩm thành trang chủ: 63% các trang bị hợp nhất và xóa bỏ - Không thêm
rel="next"/"prev"vào phân trang bình luận: Sẽ làm phân tán quyền lực trang chủ
Nội dung bị lọc vì vấn đề chất lượng
Theo báo cáo thuật toán của Google năm 2023, 61% các trang có chỉ mục thấp là do vấn đề chất lượng nội dung
Khi tỷ lệ tương tự trên trang vượt quá 32%, khả năng lập chỉ mục giảm xuống 41%, và các trang tải trên di động mất hơn 2,5 giây sẽ giảm mức độ ưu tiên thu thập.
Nội dung trùng lặp phá hủy độ tin cậy
Tiêu chuẩn trong danh sách đen ngành:
- Trang được tạo ra từ cùng một mẫu (ví dụ: trang sản phẩm) có độ tương đồng trên 32%: tỷ lệ lập chỉ mục giảm xuống 41%
- Khi độ trùng lặp đoạn văn trên 15% theo Copyscape, việc hợp nhất chỉ mục sẽ được kích hoạt
Trường hợp thực tế:
Một trang web bán buôn quần áo đã tạo ra 5.200 trang sản phẩm với mô tả giống nhau. Tuy nhiên, Google chỉ lập chỉ mục trang chủ (với cảnh báo “có trang thay thế” trên Search Console), lượng truy cập tự nhiên giảm 89% trong vòng một tuần
Giải pháp cơ bản:
- Sử dụng thư viện difflib của Python để tính toán độ tương đồng của các trang và xóa bỏ các trang có độ trùng lặp trên 25%
- Đối với các trang tương tự cần thiết (ví dụ: trang theo khu vực), thêm thông tin khu vực vào
<meta name="description"> - Thêm thẻ
rel="canonical"vào các trang trùng lặp để chỉ định phiên bản chính
<link rel="canonical" href="https://example.com/product-a?color=red" /> ▍ Hiệu suất tải vượt quá giới hạn chấp nhận được
Core Web Vitals – Ranh giới sống còn:
- FCP (First Contentful Paint) trên di động > 2.5 giây → Ưu tiên thu thập dữ liệu giảm xuống
- CLS (Cumulative Layout Shift) > 0.25 → Thời gian chờ chỉ mục tăng gấp 3 lần
Bài học rút ra:
Một trang tin tức do không nén ảnh trên màn hình đầu tiên (trung bình 4.7MB) dẫn đến LCP (Largest Contentful Paint) trên di động lên đến 8.3 giây, 12.000 bài viết bị Google đánh dấu là “nội dung giá trị thấp”.
Danh sách tối ưu hóa siêu tốc:
✅ Thay thế PNG/JPG bằng WebP và nén hàng loạt bằng Squoosh xuống ≤150KB
✅ Nội tuyến CSS cho màn hình đầu tiên, tải JS không quan trọng theo phương thức bất đồng bộ (thêm thuộc tính async hoặc defer)
✅ Lưu trữ script bên thứ ba trong localStorage để giảm yêu cầu từ bên ngoài (ví dụ: sử dụng GTM để lưu trữ Google Analytics)
▍ Thiếu dữ liệu có cấu trúc dẫn đến giảm độ ưu tiên
Quy tắc trọng số thu thập dữ liệu của bot tìm kiếm:
- Trang có FAQ Schema → Tốc độ lập chỉ mục tăng 37%
- Không có bất kỳ đánh dấu cấu trúc nào → Thời gian chờ trong hàng đợi chỉ mục kéo dài đến 14 ngày
Trường hợp điển hình:
Một trang web y tế đã thêm đánh dấu chi tiết bệnh lý MedicalSchema trên trang bài viết, khiến phạm vi chỉ mục tăng từ 55% lên 92%, và thứ hạng của từ khóa dài tăng 300%.
Mã thực tế:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "Cách cải thiện việc lập chỉ mục của Google?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Tối ưu cấu trúc sitemap và tốc độ tải trang"
}
}]
}
</script> Cấu hình máy chủ làm giảm hiệu quả thu thập dữ liệu
Lạm dụng tham số Crawl-delay
Cơ chế phản ứng của Googlebot:
- Cài đặt
Crawl-delay: 10→ Số lượng thu thập tối đa mỗi ngày giảm mạnh từ 5000 trang xuống còn 288 trang - Trạng thái mặc định không giới hạn → Googlebot thu thập trung bình 0.8 trang mỗi giây (tự động điều chỉnh theo tải của máy chủ)
Trường hợp thực tế:
Một diễn đàn đã cài đặt Crawl-delay: 5 trong tệp robots.txt để ngăn ngừa quá tải máy chủ, kết quả là số lượng thu thập của Google giảm từ 820.000 lần mỗi tháng xuống còn 43.000 lần và việc lập chỉ mục nội dung mới bị trễ tới 23 ngày.
Chiến lược sửa chữa:
- Xóa khai báo Crawl-delay (Google rõ ràng bỏ qua tham số này)
- Sử dụng giới hạn thu thập cho các bot cụ thể như
Googlebot-News - Cấu hình giới hạn tốc độ thông minh trong Nginx:
# Chỉ cho phép Googlebot và Bingbot truy cập
limit_req_zone $anti_bot zone=googlerate:10m rate=10r/s;
location / {
if ($http_user_agent ~* (Googlebot|bingbot)) {
limit_req zone=googlerate burst=20 nodelay;
}
} Chặn nhầm dải IP
Đặc điểm của dải IP Googlebot:
- Dải IPv4: 66.249.64.0/19, 34.64.0.0/10 (thêm vào năm 2023)
- Dải IPv6: 2001:4860:4801::/48
Trường hợp sai lầm:
Một trang thương mại điện tử đã chặn dải IP 66.249.70.* thông qua tường lửa Cloudflare (nhầm lẫn với cuộc tấn công của bot), khiến Googlebot không thể thu thập dữ liệu trong 17 ngày liên tiếp, và số lượng trang được lập chỉ mục giảm 62%.
Thêm quy tắc vào tường lửa Cloudflare: (ip.src in {66.249.64.0/19 34.64.0.0/10} and http.request.uri contains "/*") → Allow
Chặn các tài nguyên quan trọng cho việc render
Danh sách bị chặn:
- Chặn
*.cloudflare.com→ Làm cho 67% CSS/JS không thể tải được - Chặn Google Fonts → Tỷ lệ layout trên di động bị hỏng lên tới 89%
Ví dụ:
Một nền tảng SAAS đã chặn tên miền jquery.com, dẫn đến khi Googlebot render trang web gặp lỗi JS, tỷ lệ phân tích HTML của trang tài liệu sản phẩm chỉ còn 12%
Giải pháp mở chặn:
1. Thêm vào danh sách trắng trong cấu hình Nginx:
location ~* (jquery|bootstrapcdn|cloudflare)\.(com|net) {
allow all;
add_header X-Static-Resource "Unblocked";
} 2. Thêm thuộc tính crossorigin="anonymous" vào các tài nguyên tải không đồng bộ:
<script src="https://example.com/analytics.js" crossorigin="anonymous">script> Thời gian phản hồi của máy chủ quá thời gian
Ngưỡng chấp nhận của Google:
- Thời gian phản hồi > 2000ms → Tỷ lệ kết thúc sớm của phiên tăng 80%
- Số lượng yêu cầu xử lý mỗi giây < 50 → Ngân sách thu thập giảm xuống 30%
Ví dụ thất bại:
Một trang WordPress không kích hoạt OPcache, khiến thời gian truy vấn cơ sở dữ liệu lên tới 4,7 giây, dẫn đến tỷ lệ hết thời gian phản hồi của Googlebot tăng lên 91%, làm gián đoạn việc lập chỉ mục
Tối ưu hóa hiệu suất:
1. Cấu hình tối ưu PHP-FPM (tăng gấp 3 lần đồng thời):
pm = dynamic
pm. max_children = 50
pm. start_servers = 12
pm. min_spare_servers = 8
pm. max_spare_servers = 302. Tối ưu hóa chỉ mục MySQL bắt buộc:
ALTER TABLE wp_posts FORCE INDEX (type_status_date);Với phương pháp trên, bạn có thể kiểm soát sự khác biệt của chỉ mục ổn định dưới 5%.
Nếu bạn muốn tăng cường lượng truy cập từ Google, vui lòng tham khảo hướng dẫn GPC Crawler Pool của chúng tôi.



