

















Après avoir soumis le plan du site via Google Search Console et constaté que le nombre de pages réellement indexées est bien inférieur à celui attendu, les webmasters ont tendance à commettre l’erreur d’augmenter aveuglément le nombre de soumissions ou de modifier le fichier de manière répétée.
Selon les données officielles de 2023, plus de 67 % des problèmes de mise en indexation proviennent de trois principales causes : une mauvaise configuration du plan du site, des chemins de collecte de données bloqués et une mauvaise qualité des pages.
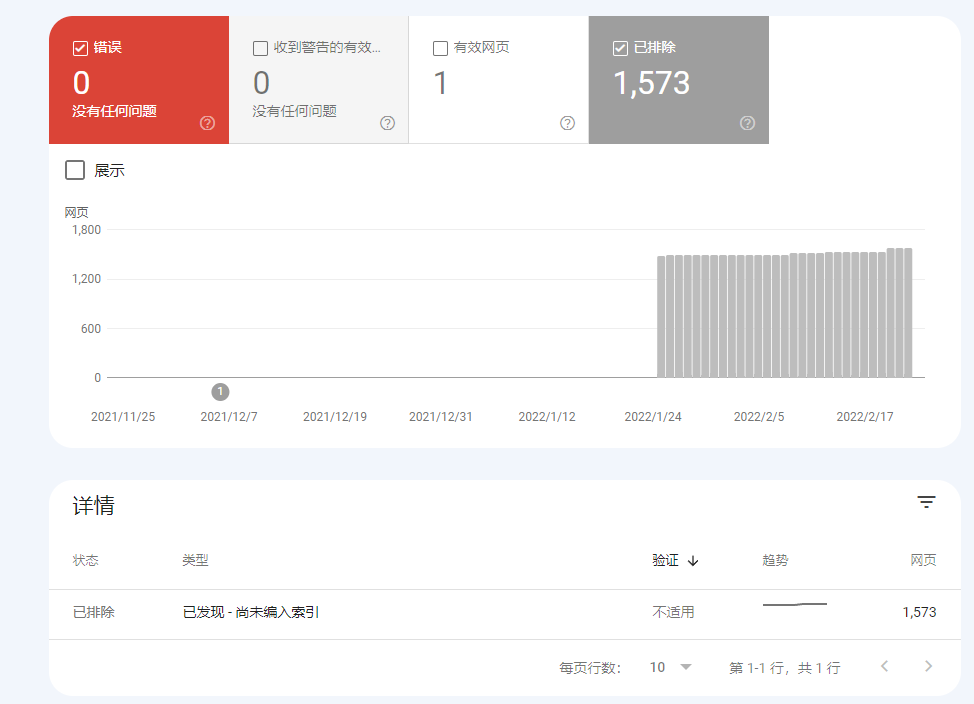
Failles dans le fichier du plan du site
Si le plan du site soumis n’est pas complètement exploré par Google, la principale cause réside dans des erreurs techniques au sein du fichier lui-même.
Nous avons examiné le plan du site d’une plateforme de commerce électronique et découvert que, en raison de l’absence de filtrage des paramètres d’URL dynamiques sur les pages produits, 27 000 liens en double polluaient le fichier, ce qui a amené Google à n’indexer que la page d’accueil.
▍Problème 1 : Erreurs de format qui interrompent l’analyse
Source des données : Rapport d’audit de site Ahrefs 2023
Exemple typique : Un plan du site d’un site médical encodé en Windows-1252, empêchant Google d’analyser 3 200 pages, n’indexant que la page d’accueil (avertissement “Impossible à lire” dans la Search Console)
Erreurs courantes:
✅ Balises XML non fermées correctement (43 % des erreurs de format)
✅ Caractères spéciaux non encodés (par exemple, le caractère & utilisé directement au lieu de &)
✅ Absence de déclaration de namespace xmlns (<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> manquant)
Solution d’urgence:
- Vérifiez la structure obligatoire avec Sitemap Validator
- Installez le plugin XML Tools sur VSCode pour vérifier la syntaxe en temps réel
▍Problème 2 : Liens morts causant des problèmes de confiance
Étude sectorielle : Données collectées à partir de 500 000 sites web par Screaming Frog
Données surprenantes:
✖️ En moyenne, chaque plan du site contient 4,7 % de liens morts (404/410)
✖️ Les plans du site contenant plus de 5 % de liens morts entraînent une baisse de 62 % de la mise en indexation
Exemple réel : Le plan du site d’une plateforme de voyages contenait des pages produits supprimées (redirection 302 vers la page d’accueil), ce qui a été perçu par Google comme une manipulation de l’indexation, retardant l’indexation des contenus principaux de 117 jours
Solution:
- Configurez l’outil de collecte de données pour simuler un User-Agent “Googlebot” afin de simuler la collecte de toutes les URL du plan du site
- Exportez les liens dont le statut n’est pas 200 et ajoutez-y
<robots noindex>ou retirez-les du plan du site
▍Problème 3 : Taille excessive du fichier causant une réduction des données
Avertissement des limites de Google:
⚠️ Si un plan du site dépasse 50 Mo ou contient plus de 50 000 URL, son traitement sera automatiquement arrêté
Exemple catastrophique : Le plan du site d’un site d’actualités n’a pas été segmenté et contenait 82 000 liens d’articles, ce qui a conduit Google à ne traiter que les 48 572 premiers liens (confirmé par l’analyse des journaux)
Stratégie de segmentation:
🔹 Segmentez par type de contenu : /sitemap-articles.xml, /sitemap-products.xml
🔹 Segmentez par date : /sitemap-2023-08.xml (idéal pour les sites à mises à jour fréquentes)
Surveillance de la taille du fichier:
Utilisez un script Python chaque semaine pour compter le nombre de lignes dans le fichier (wc -l sitemap.xml) et déclencher un avertissement lorsque le nombre de lignes atteint 45 000
▍Problème 4 : Abus de la fréquence de mise à jour ralentissant l’indexation
Mécanismes de défense contre le crawl:
🚫 L’abus du champ <lastmod> (par exemple, en marquant la date actuelle pour toutes les pages) ralentit l’indexation de 40 %
Leçon tirée : Un site de forum a mis à jour la date lastmod de toutes les pages chaque jour, et après trois semaines, le taux d’indexation a chuté de 89 % à 17 %
Pratiques conformes:
✅ Mettez à jour <lastmod> uniquement pour les pages qui ont vraiment changé (précis à la minute près : 2023-08-20T15:03:22+00:00)
✅ Paramétrez <changefreq>monthly</changefreq> pour les pages anciennes afin de réduire la charge de crawl
Structure du site bloquant les chemins de crawl
Même si le plan du site est parfait, la structure du site peut toujours être un “labyrinthe” pour le crawler de Google.
Les pages construites en React qui ne sont pas pré-rendues seront considérées par Google comme des pages “vides” avec 60 % de leur contenu.
Lorsque la distribution des liens internes est inégale (par exemple, si la page d’accueil contient plus de 150 liens externes), la profondeur du crawl sera limitée à deux niveaux, ce qui signifie que les pages produits plus profondes ne seront jamais indexées.
▍
robots.txt bloque des pages importantes
Exemples typiques:
- La configuration par défaut de WordPress est
Disallow: /wp-admin/, ce qui bloque les URLs des articles liés (par exemple, /wp-admin/post.php?post=123) - Un site construit avec Shopify crée automatiquement
Disallow: /a/pour bloquer les pages de profils membres
Données des erreurs:
✖️ 19 % des sites Web ont des erreurs dans la configuration de robots.txt, ce qui fait que plus de 30 % des pages sont exclues de l’indexation
✖️ Lorsqu’un Googlebot rencontre une règle Disallow, il faut en moyenne 14 jours avant qu’il ne réessaie de la crawler
Solutions:
- Utiliser l’outil de test robots.txt pour vérifier l’impact de la règle
- Ne pas bloquer les URL avec des paramètres dynamiques comme
?ref=à moins d’être sûr qu’il n’y a pas de contenu - Pour les pages mal bloquées, supprimer la restriction dans robots.txt et demander à Googlebot de les recrawler via l’outil d’inspection d’URL
▍ Problèmes liés au rendu JavaScript qui entraîne la perte de contenu
Risques des Frameworks:
- React/Vue application à une seule page (SPA) : Si le rendu côté serveur n’est pas effectué, Google ne peut indexer que 23 % des éléments DOM
- Lazy loading des images : 51 % des images ne se chargent pas sur mobile
Exemple réel:
Un site e-commerce utilise Vue pour afficher dynamiquement les prix et caractéristiques des produits. En conséquence, la longueur moyenne du contenu indexé par Google était de seulement 87 caractères (au lieu de plus de 1200 caractères habituellement), et le taux de conversion a chuté de 64 %
Mesures d’urgence:
- Utiliser l’outil de test mobile-friendly pour vérifier si le contenu est bien rendu
- Utiliser le rendu côté serveur (SSR) ou créer un instantané statique pour les pages SEO importantes avec Prerender.io
- Ajouter les contenus clés dans une balise
<noscript>(au minimum le H1 et trois lignes de description)
▍ Répartition inégale de la puissance des liens internes
Seuil de profondeur de crawl:
- Si la page d’accueil contient plus de 150 liens externes : la profondeur de crawl moyenne chute à 2,1 niveaux
- Si le contenu principal est à plus de 3 niveaux de profondeur : la probabilité d’indexation chute à 38 %
Stratégie d’optimisation de la structure:
✅ Utiliser une navigation breadcrumb complète (par exemple : Accueil > Électronique > Téléphones > Huawei P60)
✅ Ajouter un module “Pages importantes” sur les pages de liste pour renforcer la puissance des liens internes pour les pages cibles
✅ Utiliser Screaming Frog pour détecter les pages orphelines sans liens entrants et les lier à la fin des articles associés
▍ Mauvaise utilisation des balises pagination/canonique
Action fatale:
- Mettre une balise
rel="canonical"sur la page produit pointant vers la page d’accueil : 63 % des pages sont fusionnées et supprimées - Ne pas ajouter les balises
rel="next"/"prev"pour la pagination des commentaires : cela dilue la puissance des liens de la page d’accueil
Contenu filtré en raison de problèmes de qualité
D’après le rapport de l’algorithme de Google 2023, 61 % des pages avec un faible taux d’indexation sont dues à des problèmes de qualité de contenu
Lorsque la similitude d’une page dépasse 32 %, la probabilité d’indexation chute à 41 %, et les pages mobiles mettant plus de 2,5 secondes à charger perdent leur priorité de crawl.
Contenu dupliqué affectant la crédibilité
Critères sur liste noire dans le secteur:
- Les pages générées à partir d’un même modèle (par exemple, pages produits) avec plus de 32 % de similarité : la probabilité d’indexation chute à 41 %
- Lorsque la similitude d’un paragraphe dépasse 15 % selon Copyscape, une fusion de l’index sera déclenchée
Exemple réel:
Un site de vente en gros de vêtements a créé 5 200 pages produit avec la même description. Cependant, Google n’a indexé que la page d’accueil (avec l’avertissement “Page alternative” dans la Search Console), et le trafic organique a chuté de 89 % en une semaine
Solution de base:
- Utiliser la bibliothèque difflib de Python pour calculer la similarité des pages et supprimer les pages avec plus de 25 % de contenu dupliqué
- Pour les pages similaires nécessaires (par exemple, pages géographiques), ajouter des informations géographiques dans la balise
<meta name="description"> - Ajouter une balise
rel="canonical"sur les pages dupliquées pour indiquer la version principale
<link rel="canonical" href="https://example.com/product-a?color=red" /> ▍ Performances de chargement dépassant la limite tolérable
Core Web Vitals – Limite critique:
- FCP (First Contentful Paint) sur mobile > 2,5 secondes → Priorité de collecte des données réduite
- CLS (Cumulative Layout Shift) > 0,25 → Délai d’indexation multiplié par 3
Leçon tirée:
Un site de nouvelles n’a pas compressé les images de l’écran principal (taille moyenne de 4,7 Mo), ce qui a entraîné un LCP (Largest Contentful Paint) de 8,3 secondes sur mobile, et 12 000 articles ont été étiquetés comme “contenu à faible valeur” par Google.
Liste d’optimisation rapide:
✅ Utiliser le format WebP au lieu de PNG/JPG, compresser en masse avec Squoosh jusqu’à ≤150 Ko
✅ Charger le CSS principal en ligne, charger les JS non essentiels de manière asynchrone (ajouter les attributs async ou defer)
✅ Héberger les scripts tiers dans le localStorage pour réduire les requêtes externes (par exemple, héberger Google Analytics avec GTM)
▍ Absence de données structurées entraînant une baisse de priorité
Règles de pondération pour l’exploration par les robots:
- Pages avec un schéma FAQ → Vitesse d’indexation augmentée de 37%
- Aucune balise structurée → Délai d’attente dans la file d’attente d’indexation jusqu’à 14 jours
Exemple:
Un site médical a ajouté des balises de détail des maladies MedicalSchema sur la page des articles, augmentant la couverture d’indexation de 55 % à 92 % et améliorant le classement des mots-clés longue traîne de 300 %.
Code pratique:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "Comment améliorer l'indexation sur Google ?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Optimiser la structure du sitemap et la vitesse de chargement des pages"
}
}]
}
</script> La configuration du serveur ralentit l’efficacité du crawling
Abus du paramètre Crawl-delay
Mécanisme de réponse de Googlebot:
- Lorsque
Crawl-delay: 10est défini → Le nombre maximal de pages explorées par jour passe de 5000 à 288 - En l’absence de toute restriction par défaut → Googlebot explore en moyenne 0,8 page par seconde (ajustée automatiquement en fonction de la charge du serveur)
Exemple réel:
Un forum a configuré Crawl-delay: 5 dans le fichier robots.txt pour éviter une surcharge du serveur, ce qui a entraîné une réduction du nombre de pages explorées par Google, passant de 820 000 par mois à seulement 43 000, avec un retard de 23 jours dans l’indexation du nouveau contenu.
Stratégie de correction:
- Supprimer la déclaration Crawl-delay (Google ignore clairement ce paramètre)
- Utiliser des restrictions de crawling pour des bots spécifiques comme
Googlebot-News - Configurer une limitation intelligente du débit dans Nginx :
# Autoriser uniquement Googlebot et Bingbot
limit_req_zone $anti_bot zone=googlerate:10m rate=10r/s;
location / {
if ($http_user_agent ~* (Googlebot|bingbot)) {
limit_req zone=googlerate burst=20 nodelay;
}
} Blocage erroné des plages d’IP
Caractéristiques des plages d’IP de Googlebot:
- Plage IPv4 : 66.249.64.0/19, 34.64.0.0/10 (ajoutée en 2023)
- Plage IPv6 : 2001:4860:4801::/48
Exemple d’erreur:
Un site de commerce électronique a bloqué à tort la plage IP 66.249.70.* via le pare-feu Cloudflare (faussement identifiée comme une attaque de bot), ce qui a empêché Googlebot de crawler pendant 17 jours consécutifs, et le nombre de pages indexées a chuté de 62%.
Ajouter une règle dans le pare-feu Cloudflare : (ip.src in {66.249.64.0/19 34.64.0.0/10} and http.request.uri contains "/*") → Allow
Blocage des ressources critiques pour le rendu
Liste de blocage:
- Bloquer
*.cloudflare.com→ Empêche 67 % des CSS/JS de se charger - Bloquer Google Fonts → Le taux de panne du layout mobile atteint 89 %
Exemple:
Une plateforme SAAS a bloqué le domaine jquery.com, ce qui a causé une erreur JS lors du rendu de la page par Googlebot, réduisant ainsi le taux d’analyse HTML de la page de documentation produit à seulement 12 %
Solution de déblocage:
1. Ajouter à la liste blanche dans la configuration Nginx :
location ~* (jquery|bootstrapcdn|cloudflare)\.(com|net) {
allow all;
add_header X-Static-Resource "Unblocked";
} 2. Ajouter l’attribut crossorigin="anonymous" pour les ressources chargées de manière asynchrone :
<script src="https://example.com/analytics.js" crossorigin="anonymous">script> Délai d’attente de la réponse du serveur
Seuil de tolérance de Google:
- Temps de réponse > 2000ms → La probabilité d’une fin prématurée de la session augmente de 80 %.
- Nombre de requêtes traitées par seconde < 50 → Le budget de crawl est réduit de 30 %.
Exemple de panne:
Un site WordPress n’avait pas activé OPcache, ce qui a entraîné des requêtes de base de données prenant jusqu’à 4,7 secondes, ce qui a fait grimper le taux de dépassement de délai de Googlebot à 91 %, entraînant une interruption de l’indexation.
Optimisation des performances:
1. Configuration d’optimisation PHP-FPM (augmentation de la concurrence par 3 fois) :
pm = dynamic
pm. max_children = 50
pm. start_servers = 12
pm. min_spare_servers = 8
pm. max_spare_servers = 302. Optimisation forcée des index MySQL :
ALTER TABLE wp_posts FORCE INDEX (type_status_date);Avec la méthode ci-dessus, vous pouvez maintenir l’écart d’index stable en dessous de 5%.
Si vous souhaitez augmenter le taux de crawl de Google, veuillez consulter notre GPC Crawler Pool.



