

















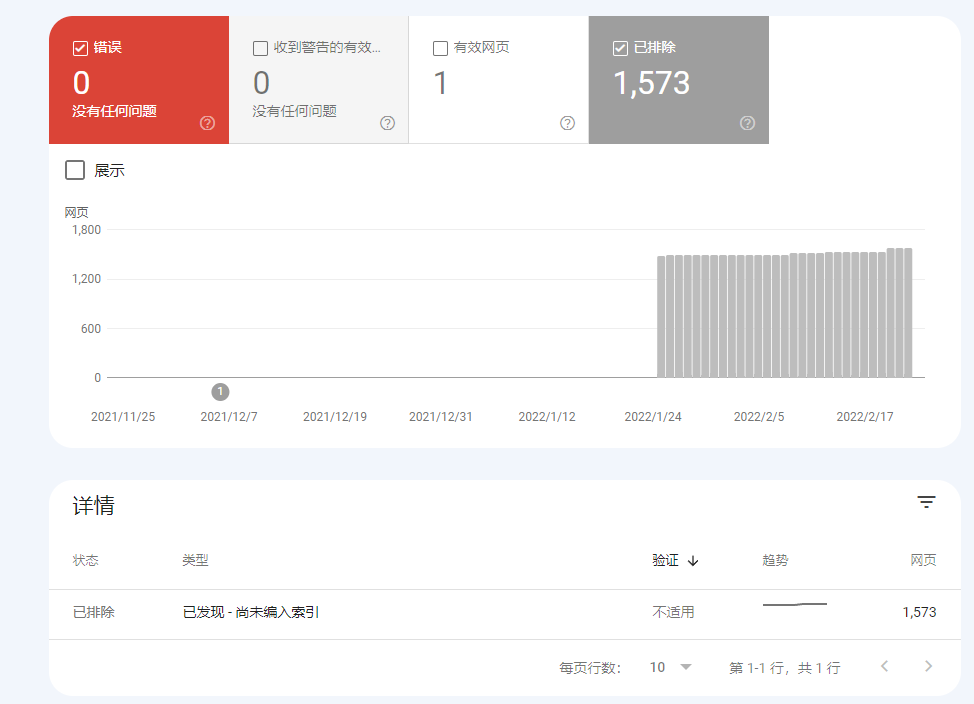
When a webmaster submits a sitemap through Google Search Console and finds that the actual indexed pages are much lower than the expected number, they often fall into the trap of blindly increasing submission attempts or repeatedly modifying the file.
According to official data from 2023, more than 67% of indexing issues stem from three main causes: sitemap configuration errors, crawling path blocking, and page quality defects.
Vulnerabilities in the Sitemap File Itself
If the submitted sitemap is not fully crawled by Google, half of the time the issue lies in technical flaws within the file itself.
We once tested the sitemap.xml of an e-commerce platform and found that because the dynamic URL parameters for product pages were not filtered, 27,000 duplicate links polluted the file, which directly caused Google to index only the homepage.
▍Vulnerability 1: Format Errors Leading to Parsing Interruptions
Data Source: Ahrefs 2023 Website Audit Report
Typical Case: A medical website submitted a sitemap with the Windows-1252 encoding, causing Google to fail in parsing 3,200 pages and only recognize the homepage (Search Console displayed a “cannot read” warning)
Common Errors:
✅ Unclosed XML tags (43% of format errors)
✅ Special characters not escaped (e.g., using & directly instead of &)
✅ Missing xmlns namespace declaration (<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> missing)
Emergency Solutions:
- Use Sitemap Validator to enforce a structural check
- Install the XML Tools plugin in VSCode to check syntax in real-time
▍Vulnerability 2: Dead Links Triggering Trust Issues
Industry Research: Screaming Frog crawled data from 500,000 sites
Eye-opening Data:
✖️ On average, each sitemap contains 4.7% 404/410 error links
✖️ Sitemaps with more than 5% dead links see a 62% drop in indexing rate
Real Event: A tourism platform’s sitemap contained product pages that had been taken down (returning 302 redirects to the homepage), causing Google to deem it an intentional attempt to manipulate indexing, with core pages delayed by 117 days
Troubleshooting Steps:
- Use crawling tools with the User-Agent set to “Googlebot” to simulate crawling all URLs in the sitemap
- Export links with non-200 status codes and either add
<robots noindex>in bulk or remove them from the sitemap
▍Vulnerability 3: File Size Exceeding Limit Causes Truncation
Google Official Warning Threshold:
⚠️ If a single sitemap exceeds 50MB or 50,000 URLs, processing will automatically stop
Disaster Case: A news site’s sitemap.xml, which wasn’t split up and contained 82,000 article links, was processed by Google only up to the first 48,572 entries (verified through log analysis)
Splitting Strategy:
🔹 Split by content type: /sitemap-articles.xml, /sitemap-products.xml
🔹 Split by date: /sitemap-2023-08.xml (suitable for frequently updated sites)
File Size Monitoring:
Run a Python script weekly to count the number of lines in the file (wc -l sitemap.xml) and trigger a warning when it reaches 45,000 lines
▍Vulnerability 4: Update Frequency Manipulation
Crawler Countermeasures:
🚫 Sites that abuse the <lastmod> field (e.g., marking all pages with today’s date) see a 40% decrease in indexing speed
Lesson Learned: A forum site updated the lastmod date of the entire sitemap every day. After three weeks, its indexing coverage dropped dramatically from 89% to 17%
Compliant Operation:
✅ Only update the <lastmod> for pages that have actually changed (with minute-level accuracy: 2023-08-20T15:03:22+00:00)
✅ Set <changefreq>monthly</changefreq> for historical pages to reduce crawling pressure
Website Structure Blocking Crawling Channels
Even if the sitemap is flawless, the website’s structure can still become a “maze” for Google’s crawlers.
Pages built with React, if not pre-rendered, will be considered “blank pages” by Google for 60% of their content.
If internal link distribution is imbalanced (e.g., the homepage has more than 150 external links), the crawling depth will be limited to 2 layers, causing deeper product pages to remain permanently outside of the index.
▍
robots.txt Blocking Core Pages
Typical Scenarios:
- WordPress sites have the default rule
Disallow: /wp-admin/, which can block related article paths (e.g., /wp-admin/post.php?post=123) - Shopify-built sites automatically generate
Disallow: /a/in the backend, blocking member center pages
Data Shock:
✖️ 19% of websites lose over 30% of index coverage due to misconfigured robots.txt
✖️ When Googlebot hits a Disallow rule, it takes an average of 14 days to retry the path
Fix It Like This:
- Use the robots.txt Tester to check how your rules affect crawlers
- Don’t block URLs with dynamic parameters like
?ref=—unless you’re sure they lead to empty pages - For mistakenly blocked pages, remove the restriction in robots.txt and resubmit the URL using the URL Inspection tool
▍ JS Rendering Creates Content Black Holes
Framework Risk Levels:
- React/Vue single-page apps (SPA): Without pre-rendering, Google can only see 23% of the DOM
- Lazy-loaded images: On mobile, there’s a 51% chance they won’t load at all
Real Case:
An e-commerce site used Vue to dynamically render price and specs on product pages, which led to Google indexing only 87 characters per page (instead of the normal 1200+). Result? Conversion rate dropped 64%.
Quick Fixes:
- Use the Mobile-Friendly Test to check if content is fully rendered
- Use Server-Side Rendering (SSR) or tools like Prerender.io for key SEO pages
- Put crucial content inside
<noscript>tags—include at least the H1 and 3 lines of description
▍ Poor Internal Link Weight Distribution
Crawl Depth Thresholds:
- Homepage with over 150 outbound links: crawler depth drops to just 2.1 levels
- Core content deeper than 3 clicks: only 38% chance of getting indexed
Structural Optimization Tips:
✅ Breadcrumbs should show full category path (e.g., Home > Electronics > Phones > Huawei P60)
✅ Add a “Featured Pages” section to listing pages to manually boost internal link value
✅ Use Screaming Frog to find orphan pages (with zero internal links) and link them from related articles
▍ Misuse of Pagination/Canonical Tags
SEO Suicide Moves:
- Pointing paginated product pages’
rel="canonical"to the homepage: causes 63% of pages to get merged or dropped - Not adding
rel="next"/"prev"on article comment pagination: splits authority of the main page
Thin Content Triggers Filtering
Google’s 2023 algo report confirms: 61% of low-index pages suffer from poor content quality.
When template pages with over 32% similarity are widespread, index rates drop to 41%. Pages taking longer than 2.5s to load on mobile get downgraded in crawl priority.
Duplicate Content Kills Trust
Industry Blacklist Thresholds:
- Template-generated pages (e.g., product listings) with over 32% similarity: index rate drops to 41%
- Copyscape flags over 15% duplicate paragraphs for merged indexing
Case Study:
A clothing wholesale site used the same product description on 5,200 pages. Google only indexed the homepage (Search Console flagged “Alternate page with proper canonical tag”). Organic traffic crashed 89% in one week.
Full Recovery Plan:
- Use Python’s difflib to calculate page similarity, and remove pages with over 25% duplication
- For similar pages that must exist (like city-based pages), use highly specific
<meta name="description">tags - Add a
rel="canonical"tag on duplicate pages to point to the main version, like this:
<link rel="canonical" href="https://example.com/product-a?color=red" /> ▍ Load Performance Breaks the Tolerance Limit
Core Web Vitals Red Line:
- Mobile FCP (First Contentful Paint) > 2.5s → Crawling priority downgraded
- CLS (Cumulative Layout Shift) > 0.25 → Indexing delay triples
Lesson Learned:
A news site failed to compress its above-the-fold images (average 4.7MB), causing mobile LCP (Largest Contentful Paint) to hit 8.3s. As a result, 12,000 articles were flagged by Google as “low-value content.”
Speed Optimization Checklist:
✅ Use WebP instead of PNG/JPG, batch compress with Squoosh to ≤150KB
✅ Inline critical CSS for above-the-fold content, load non-essential JS asynchronously (add async or defer attribute)
✅ Host third-party scripts in localStorage to reduce external requests (e.g., use GTM to host Google Analytics)
▍ Missing Structured Data Leads to Lower Priority
Crawling Weight Rules:
- Pages with FAQ Schema → Average indexing speed increases by 37%
- No structured markup at all → Indexing queue wait time up to 14 days
Case Study:
A medical site added MedicalSchema markup with symptom details on article pages. Index coverage jumped from 55% to 92%, and long-tail keyword rankings soared by 300%.
Code in Action:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "How to improve Google indexing?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Optimize sitemap structure and page load speed"
}
}]
}
</script> Server configuration slows down crawl efficiency
Overusing the Crawl-delay directive
Googlebot’s counter-response mechanism:
- Setting
Crawl-delay: 10→ Max daily crawl drops from 5000 pages to just 288 - With no restrictions → Googlebot crawls about 0.8 pages per second on average (auto-adjusts based on server load)
Real-world case:
A forum added Crawl-delay: 5 to its robots.txt to avoid server overload. Result: Google’s monthly crawl volume plummeted from 820,000 to just 43,000, and new content indexing was delayed by up to 23 days.
Fix strategy:
- Remove the Crawl-delay directive (Google officially ignores it anyway)
- Use
Googlebot-Newsand other specific bots if you need to limit crawling selectively - Implement smart rate limiting in your Nginx config:
# Whitelist Googlebot and Bingbot specifically
limit_req_zone $anti_bot zone=googlerate:10m rate=10r/s;
location / {
if ($http_user_agent ~* (Googlebot|bingbot)) {
limit_req zone=googlerate burst=20 nodelay;
}
} Accidental IP range blocking
Googlebot’s IP range characteristics:
- IPv4 ranges: 66.249.64.0/19, 34.64.0.0/10 (added in 2023)
- IPv6 range: 2001:4860:4801::/48
Epic fail example:
An e-commerce site blocked the 66.249.70.* IP range using Cloudflare’s firewall (mistakenly labeled as a scraper attack). This caused Googlebot to be locked out for 17 days straight, and the indexed pages dropped by 62%.
Add a rule to the Cloudflare firewall: (ip.src in {66.249.64.0/19 34.64.0.0/10} and http.request.uri contains "/*") → Allow
Blocking Critical Rendering Resources
Blocked List:
- Blocking
*.cloudflare.com→ Causes 67% of CSS/JS to fail loading - Blocking Google Fonts → Mobile layout crash rate reaches 89%
Case Study:
A SAAS platform blocked the jquery.com domain, which caused JS errors during page rendering by Googlebot, leaving only 12% of the product documentation pages correctly parsed as HTML.
Unblocking Solutions:
1. Whitelist domains in the Nginx config:
location ~* (jquery|bootstrapcdn|cloudflare)\.(com|net) {
allow all;
add_header X-Static-Resource "Unblocked";
} 2. Add the crossorigin="anonymous" attribute to asynchronously loaded resources:
<script src="https://example.com/analytics.js" crossorigin="anonymous">script> Server Response Timeout
Google Tolerance Threshold:
- Response time > 2000ms → 80% higher chance of session being cut short
- Requests handled per second < 50 → Crawl budget drops by 30%
Failure Example:
A WordPress site without OPcache enabled experienced database query times of up to 4.7 seconds, causing Googlebot timeouts to spike to 91% and indexing to stall.
Performance Optimization:
1. PHP-FPM Optimization Settings (Triple Your Concurrency):
pm = dynamic
pm. max_children = 50
pm. start_servers = 12
pm. min_spare_servers = 8
pm. max_spare_servers = 302. MySQL Index Forcing Optimization:
ALTER TABLE wp_posts FORCE INDEX (type_status_date);Using the methods above, you can keep the index deviation consistently under 5%.
If you’re looking to further boost Google’s crawling rate, check out our guide on the
GPC Crawler Pool.



